알고리즘 도감과 파이썬 기초& 알고리즘 사고법을 기반으로 작성된 내용입니다.
해시 테이블(hash table)은 자료구조의 하나입니다. 해시함수와 함께 데이터 검색을 효율적으로 하기 위해 사용되는 구조입니다.
장점: 해시테이블은 해시 함수를 이용해서 배열 내의 특정 데이터에 빠르게 접근할 수 있습니다. 해시값이 충돌할 때는 리스트를 사용하고 있어서 저장할 수 있는 데이터 수가 정해져 있지 않더라도 유연하게 대응할 수 있습니다.
단점: 해시 테이블에 사용하는 배열의 크기가 너무 작으면 충돌이 많아지고 선형 탬색의 빈도가 높아지게 됩니다. 반대로 크기가 너무 크면 데이터가 없는 상자가 너무 많아져서 메모리를 낭비하게 됩니다. 따라서 배열의 크기를 적절히 설정하는 것이 중요합니다.
무슨 말인지 하나하나 알아볼까요? 먼저 장점 부터.
1. 해시 함수를 사용해서 특정 데이터에 빠르게 접근 할 수 있다.
#해시함수란 ? 주어진 데이터를 고정길이의 불규칙한 숫자로 변환하는 함수를 말합니다. 불규칙한 숫자는 데이터를 요약한 것으로 다영한 상황에 적용됩니다.
책에서는 해시함수를 믹서기에 비유했는데, 데이터를 믹서기(해시함수)에 넣어 고정길이의 불규칙한 숫자로 전화 하는 것입니다.
"a,b,c,d,e,"(데이터) ====> [믹서기(해시함수)] ===== 7f0579bc2d (불규칙한 고정 길이 데이터로 출력)

해시함수는 데이터를 분리하는 기계라고 생각하면 쉬운데, 이 때 출력된 값을 "해시값" 이라고 합니다.
해시값은 16진수로 표기하는데, 16진수란 0~9의 숫자와 알파벳으로 이루어진 16개의 숫자를 말합니다.
해시함수의 특징
- 해시값의 데이터 길이가 고정된다.(바뀌지 않는다) : 입력 데이터에 따라 출력값의 길이가 변하지 않습니다.
- 입력값이 같으면, 출력값도 반드시 같다. : 특정데이터에 빠르게 접근할 수 있는 이유입니다.
- 전혀 다른 데이터를 입력해도 같은 해시값이 나올 수 있다. : 해시값 충돌의 문제가 발생합니다.
- 해시값으로부터 원데이터를 역산하는 것이 불가능하다. : 입력&출력이 단방향으로 이루어 지기 때문에 암호화에 사용됩니다. 키와 해시값 사이에 직접적인 연관이 없기 때문에 해시값만 가지고는 키를 온전히 복원하기 어렵기 때문입니다.
- 프로그램을 만들 때, 데이터 탐색구조를 선형이나 이진구조와 같이 설계한다면 key 와 value를 가지고 탐색을 합니다. 이런 방법은 계산시간이 O(logn)에 그치는데 이런 구조에서도 좀더 빠른 탐색의 알고리즘을 원할 때, 해시테이블 구조를 사용할 수 있습니다.
해시데이블 이용시 key에 산술적인 연산을 적용하여 (해시함수) 항목이 저장되어 있는 테이블의 주소를 계산하여 항목에 접근하므로, 다량의 데이터를 모두 탐색하지 않아도 찾을 수 있게 되는 것입니다.
해싱은 O(1)의 시간안에 탐색을 끝마칠 수도 있게 되는 것입니다.
어떤 그룹의 회원명부를 작성한다고 할 때, 회원이 100명이라면, 0~99까지 아이디를 생성하고, 크기가 100인 배열을 만들면 됩니다. 회원 자료를 저장하거나 탐색할 때, 회원 아이디를 key값으로 생각하고 배열의 특정값을 찾을 수 있습니다. 이런 계산방식이 O(1)의 시간복잡도를 가진다고 말합니다.
그러나 이 때, key값이 매우 커지거나 문자열이거나 할 경우 탐색키를 직접 배열의 인덱스로 사용하는데 무리가 있으므로, 각 탐색 키를 작은 정수로 매핑시킬 수 있는 해시함수를 사용하여 매핑합니다.
해싱이란, 어떤 항목의 key를 가지고 바로 항목이 들어있는 배열의 인덱스를 결정하는 방법이고, 해시함수를 사용하여 키를 해시값으로 매핑하고, 이 해시값을 색인(index) 혹은 주소 삼아 데이터의 값(value)을 키와 함께 저장하는 자료구조를 해시테이블(hash table)이라고 합니다.
2. 해시테이블은 충돌(collision)이 발생한다는 단점이 있다.
(자료출처: ratsgo.github.io/data%20structure&algorithm/2017/10/25/hash/)
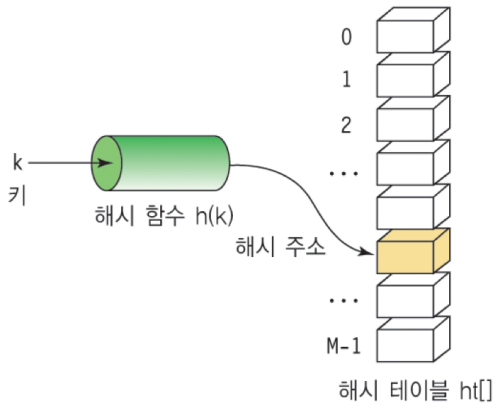
키값 k를 입력받아 해시 함수 h(k)로 연산한 결과인 해시 주소 h(k)를 인덱스로 사용하여 해시 테이블에 있는 항목에 접근합니다.
해시 테이블 ht는 M개의 버킷(bucket)으로 이루어지는 테이블로서 ht[0], ht[1], ..... , ht[M-1]의 원소를 가집니다.

하나의 버킷은 여러개의 슬롯을 가질 수 있으며, 하나의 슬롯에는 하나의 항목이 저장됩니다. 하나의 버킷에 여러개의 슬롯을 두는 이유는 서로 다른 두 개의 key가 해시함수에 의해 동일한 해시 주소호 변환될 수 있으므로 여러개의 항못을 동일한 버킷에 저장하기 위해서 입니다. 지금까지 만들어진 어떤 해시함수도 완벽히 다른 주소로 변환하는 함수는 존재하지 않으며, 동일한 주소를 반환하는 충돌문제가 발생할 수 있기 때문에 해시테이블에서는 그에 대비하여 자료구조를 생성할 때 반드시 고려해야 할 문제입니다.
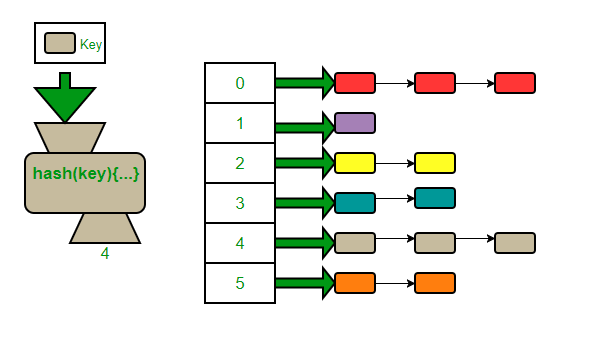
서로다른 두 개의 탐색 키 k1과 k2에 대하여 h(k1) = h(k2)인 경우를 충돌(collision)이라고 하며, 이러한 키 k1과 k2를 동의어(synonym)라 합니다. 만약 충돌이 발생하면 같은 버켓에 있는 다른 슬롯에 항목을 저장하게 됩니다. 충돌이 자주 발생하면 버켓 내부에서의 순차 탐색 시간이 길어져서 탐색 성능이 저하될 수 있으므로 해시 함수를 수정하거나 해시 테이블의 크기를 적절히 조절해주어야 하며,. 이러한 충돌이 버킷에 할당된 슬롯 수보다 많이 발생하게 되면 버킷에 더 이상 항목을 저장할 수 없게되는 오버플로우(overflow)가 발생하게 됩니다. 실제의 해싱에서는 충돌과 오버플로우가 빈번하게 발생하므로 시간복잡도는 이상적인 경우의 O(1+α)가 됩니다.
각각의 슬롯은 연결리스트로 저장됩니다. (링크드 리스트) 데이터를 아래 그림처럼 연결리스트로 저장해 둘 경우 최근 데이터는 연결리스트의 head에 추가합니다(이 경우 O(1), tail에 저장할 경우 O(n)이 됩니다.
3. 해시 테이블을 사용하는 예
(자료출처: youmekko.github.io/2018/04/02/2018-04-02-Algorithm/)
해시테이블은 어디에나 사용될 수 있습니다.
1. 조회하기
- 어떤 것을 다른 것과 연관 시키고자 할 때
- 무언가를 찾아보고자 할 때
어떤 웹사이트에 접속하든 그 주소는 모두 IP주소로 번역되어야 한다.
google → 74.125.239.133
facebook → 173.252.120.6
이런 과정을 DNS 확인(resolution)이라고 한다. 해시 테이블은 이 기능을 제공하는 방법 중의 하나이다.
2. 중복 방지
투표소 관리, 중복 투표 방지 예제.
누군가 투표를 하러온다. → 이 사람이 해시 테이블에 있는지 확인한다.
→ 예 : 돌려보낸다.
→ 아니오 : 투표를 하게한다. → 이름을 해시 테이블에 추가한다.

3.해시 테이블을 캐시로 사용하기
캐싱은 작업속도를 올리는 일반적인 방법이다. 모든 대형 웹사이트는 캐싱을 사용한다. 그리고 그 자료는 해시 테이블에 저장된다.
ULR을 호출 → 해시테이블이있는지 확인
→ 예 : 해시테이블의 내용을 전송
→ 아니오 : 서버가 무언가 작업을 함

해시 테이블의 장점
- 어떤 것과 다른것 사이의 관계를 모형화 할 수 있다.
- 중복을 막을 수 있다.
- 서버에게 작업을 시키지 않고 자료를 캐싱할 수 있다.
4. 성능
앞서 언급한 바와 같이 해시테이블은 이진탐색이나 선형탐색의 O(logn)의 시간을 O(1)이 되게 합니다.
평균적인 경우 해시 테이블은 모든 항목에 대해 O(1)시간이 걸린다. O(1)시간은 상수시간(constant time)이라고 불린다. 상수 시간은 순간적이라는 뜻이 아니라 해시테이블의 크기에 상관없이 항상 똑같은 시간이 걸린다는 의미이다. (배열에서 원소를 꺼내는 데도 상수시간이 걸린다.)

평균적인 경우에 해시 테이블의 성능을 살펴보면 탐색을 할 때는 배열 만큼 빠릅니다. 그리고 삽입이나 삭제시에는 연결 리스트만큼 빠릅니다. 양쪽의 세계에서 좋은 점만 가지는 방법이라고 할 수 있습니다. 하지만 충돌이 발생하면, 해시 테이블이 가장 느리기도 합니다. 따라서 충돌을 피하려면 낮은 사용율 / 좋은 해시 함수가 필요합니다.
###사용율
해시 테이블의 사용율 = 해시테이블에 있는 항목의 수 / 해시 테이블에 있는 공간의 수
해시 테이블은 저장을 위해 배열을 사용한다.
- 크기가 5인 배열에서 인덱스 1,3번을 사용하고 있다면 사용율은 2/5, 즉 0.4 이다.
- 크기가 3인 배열에서 인덱스 1개만 사용하고 있다면 사용을은 1/3이다.
- 100개의 value를 해시테이블에 저장해야 한다고 생각해보자.
- 배열의 크기가 100이면 사용율은 1이다.
- 배열의 크기가 50이면 사용율은 2이다.
- 사용율이 1보다 크다는 것은 배열에 공간의 수보다 항복의 수가 많다는 뜻이다. 사용율이 커지기 시작하면 해시테이블의 공간을 추가해야한다. 이것을 리사이징이라고 한다. 보통은 사용율이 0.7보다 커지면 리사이징 한다. (리사이징은 엄청 비싼 작업이다. 자주하는 것은 좋지않다.)
좋은 해시 함수 란, 배열에 값을 고루 분포시키는 함수를 말합니다.
Summary....
- 해시테이블 = 해시 함수 + 배열
- 충돌은 나쁘다. 충돌을 줄이는 좋은 해시 함수가 있어야 한다.
- 해시 테이블은 정말 빠른 탐색, 삽입, 삭제 속도를 가진다.
- 해시 테이블은 어떤 항목과 다른 항목의 관계를 모형화하는데 좋다.
- 사용율이 0.7보다 커지면 해시 테이블을 리사이징 할 때 이다.
- 해시 테이블은 (웹 서버 등에서) 테이터를 캐싱하는데도 사용한다.
- 해시 테이블은 중복을 잡아내는 데도 뛰어나다.
'AI_학습노트 > 30일 파이썬' 카테고리의 다른 글
| _06.[Python Tip]딕셔너리 tip2가지 (0) | 2021.07.03 |
|---|---|
| _05.힙(Heap) 구조 (0) | 2021.03.19 |
| _03. coma반 수업 노트필기_Part2 (0) | 2021.03.02 |
| _02. coma반 수업 노트필기_Part1 (0) | 2021.01.14 |
| _01. 파이썬 coma에서 깨어나기(진행완료 01/07~02/07) (8) | 2021.01.08 |



