Lecture1. Introduction to Deep Learning for Computer Vision.
Lecture2. Image Classification
Lecture6.Backpropagation
숙명여대 한국어 강의 [링크1] (01:01:00부터)
숙명여대 한국어 강의 [링크2]
6.1 How to compute gradients?

지난시간까지 손실함수를 구해서 경사하강법으로 손실함수가 0이 되는 최적 W를 찾아야 한다는 것과 뉴럴 네트워크에 대해서 배웠습니다. 이번 강의에서는 역전파라는 방법으로 뉴럴네트워크가 뉴런의 W와 b를 조정하여 y를 근사하는 방법에 대해서 학습합니다.
역전파의 미분 계산과정에 대해서 10분짜리 짧은 강의를 듣고 시작하겠습니다. 그리고 18분짜리 역전파(back propagation)강의도 듣고 오겠습니다.
링크된 김성훈 교수님의 강의를 듣고 오신 분들은 아시겠지만 역전파의 핵심은 아무리 복잡한 신경망 이라하더라도, 단순한 계산의 반복이라는 것을 알 수 있었을 것입니다. 역전파의 핵심은 단순한 편미분 계산을 반복하기 때문에 모델의 복잡가 높아진다고 해도 학습에 무리가 되지 않는다는 것입니다. 이것을 매우 효율적이라고 표현하더라구요.
그러면, 벌써 역전파의 절반을 훌쩍 넘어온 기분이 듭니다.
중요한 슬라이드를 하나씩 보면서 확인해 보도록 하겠습니다.

파란 박스의 선형식과 빨간색 박스의 손실함수(SVM Loss)를 도식화 한 슬라이드 입니다.
R(w)는 정규화 시켜준 것 입니다. (강의 3강) 이 부분을 아래 슬라이드에서 (+)한 것으로 표시합니다. 제일 앞의 x와 W는 파란박스의 수식처럼 곱하기 연산이고, L앞에 정규화 값 람다는 더하기 연산이 됩니다. 이것을 더 간단히 아래와 같이 나타냅니다.
이 그래프를 자세히 보면 방향성이 있다는 걸 알 수 있습니다. 이러한 연산이 x에서 L로 향하는 것을 Forward pass라고 하고, 이제 손실함수를 0으로 만들기위해서 SGD를 통해 W와 b를 조정해 나가는 연산은 반대 방향으로 진행됩니다.
그래서 backpropagation이라고 하는 것이지요.

역전파를 사용해 출력층의 비용에서 시작해서 한 층씩 신경망을 거꾸로 이동하면서 모든 파라미터의 그레디언트를 계산합니다. 파라미터의 그레디언트(미분값)를 사용해 해당 파라미터의 값을 증가 시키거나 감소시킵니다. (비용을 감소시키는 쪽으로 )
정리하자면, 역전파는 모든 파라미터가 전체 비용에 상대적으로 기여하는 양을 계산하고 이에 다라 각 파라미터를 업데이트 합니다. 이런 식으로 신경망이 반복적으로 비용을 감소 시키면 학습이 되는 것입니다. (딥러닝일러스트레이티드 P.146)
다시 슬라이드로 돌아가서, output쪽의 노드부터 전체 function인 f를 각 노드가 나타내는 함수로 편미분하여 upstream gradient를 만들고, chain rule(미분의 곱연산)을 적용시켜 local gradient(현재 노드의 gradient)를 upstream gradient과 곱해주어 상위 노드의 gradient를 계산하는 과정으로. 처음 input단의 gradient를 계산해 나가는 방식입니다.


주황색 박스안에 식을 보면 델타q는 곱의 연산이기 연쇄법칙(chain rule)에 의해 소거됩니다.

이런식으로 계속하여 출력층에서 부터 입력에 도달할 때까지 역전파가 계속됩니다. 오차 역전파법이 미분 시간을 단축시키는 이유는 체인룰로 국소미분으로 분리한 계산을 할때에는, 해당 위치에서, 해당 연산에 관련된 변수에 대해서만 우리가 알아보고자하는 변수의 기울기를 구할수 있으므로, 앞으로 갈수록 연산량이 줄어들게 되는 것입니다.
이 슬라이드에서는 하나의 입력, 하나의 은닉뉴런, 하나의 출력으로 된 신경망으로 배웠지만, 실제 딥러닝 모델은 이렇게 간단하지 않습니다. 그러나 이런 단순한 구조가 확장된다는 것이 중요합니다.

이러한 backpropagation 과정을 하나의 노드(혹은 전체 function) 관점에서 나타내면 다음 그림과 같습니다.

- 함숫값: forward pass
- 미분값: backward propagation
으로 볼 수 있습니다.
숙명여대 강의 1차는 여기서 마무리가 되네요. 다음 2차 강의로 넘어 가겠습니다.
6.2 Another Example
이제 활성화 함수가 시그모이드로 구성된 경우를 위에서 본 computational graph로 살펴 보겠습니다.
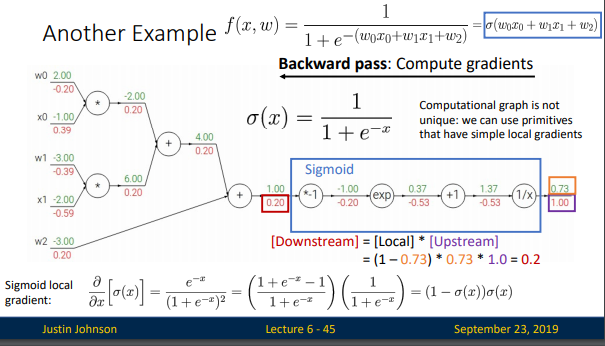
도함수를 계산하기 위한 steps
- Forward pass (초록색 숫자)
- Backward pass (빨간색 숫자)
이 슬라이드에서 중요한건, 위의 시그모이드처럼, 미리 한 노드 사이의 미분값을 구해놓으면, 이는 미분이 아니라 그냥 연산이 되는 것이고, 이렇게 노드별로, 노드를 생성시, 이에따른 역전파 계산법을 미리 만들어둔다면, 역전파시 그 값들을 뒤에서부터 차례로 곱해주기만 하면, 우리는 미분을 할 것도 없이 기울기를 구할 수 있게 됩니다.
딥러닝시 사용되는 함수는 제법 제한되어 있어서, 일단은 저와같은 수준의 비전공자 노베이스 분이시라면, 미분을 모른채 각 노드별 역전파 공식만을 외워도 이해하는데 크게 어렵지 않을것입니다.
슬라이드 47-50 까지는 순전파 만큼이나 역전파의 계산이 쉽다는걸 설명하는 슬라이드 입니다. 49 page의 summary만 내용을 정리하고 다음으로 넘어가겠습니다.
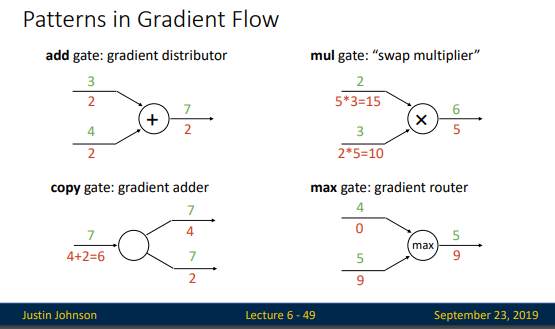
- Add gate는 결과적으로, upstream gradient를 뿌려주는 효과를 갖는다. (add gate: gradient distributor)
- copy gate 는 f(x)=(x, x) 결과적으로, upstream gradient를 더해주는 효과를 갖는다. (copy gate :swap multiplier )
- mul gate 는 결과적으로, 각각의 값을 거꾸로 곱해주는 효과를 갖는다. (mul gate: swap multiplier)
- max gate는 결과적으로, x와 y 중 값이 더 큰 쪽으로 gradient가 흐르게 된다. (max gate: gradient router)
그러면, 어떻게 코딩으로 표시하는지 확인 해 보겠습니다

sigmoid를 계산하는 식을 보자. 우선, 파란 박스의 함숫값들을 forward pass로 계산한 것이고,
빨간 박스의 코드는 위 슬라이드 49page에서 설명한 Gate의 원리를 이용하여 backward pass를 구현한 것입니다.

파이토치는 잘 모르니까.. 뉴럴네트워크 모델을 파이썬으로 짠 코드를 살짝 비교해 보자.

설명은.. 생략. -ㅅ- ;;
6.3 Backprop with vector
'AI_학습노트 > CS231n' 카테고리의 다른 글
| _10.[CS231n]Lecture7. (0) | 2021.02.15 |
|---|---|
| _08.[CS231N]Lecture5. (0) | 2021.02.14 |
| _07.[CS231N] Lecture4. (0) | 2021.02.13 |
| _06.[CS231N] Lecture3. (0) | 2021.02.13 |
| _05.[CS231N] Lecture2. (0) | 2021.02.12 |



